运输层概述
1. 概述
运输层协议的任务是为不同主机的 应用进程 之间提供 逻辑通信(logic communication)。具体的过程是:在发送端,运输层将应用程序进程需要发送的数据包装成 报文段(segment),然后将他们传递给网络层,由网络层将其封装为一个数据报后向目的地发送,接收端网络层接收到该数据后,首先发送给运输层,运输层再将该数据处理后交给对应的应用程序(端系统中的具体进程)。
从上面的描述看出,运输层协议运行在端系统中(也就是客户机或服务器中)。
网络层协议负责 主机 之间的逻辑通信,通常使用 IP 协议。IP 服务是一种 不可靠的服务(unreliable service),不确保保留顺序的,并且完整的交付数据。
运输层协议将主机之间的交付拓展到进程之间的交付,被称为 运输层的多路复用(transport-layer multiplexing)与 多路分解(demultiplexing)。(实际上就是多路应用层数据复用一个网络层的传输链路)
UDP协议提供最基础的 进程间的数据交付,以及差错检查服务。
TCP协议 则额外提供 1- 可靠的数据传输; 2- 拥塞控制 的服务。
2. 多路复用与多路分解
所谓的多路复用其实就是运输层协议控制的到各个进程的 报文段 共用一个网络层。具体地,运输层协议通过 端口号 来确定需将报文段给到具体的套接字。
因此,在报文段的头部会带有源端口号字段(source port number field) 和目的端口号字段(destination port number field),用来唯一标识一个 源系统 和 目的系统中的套接字。
端口号 是一个 16比特的数,其大小在 0-65535之间。0-1023 范围的端口号称为周知端口号(well-known port number)-限制使用,保留给如 HTTP 等常用的应用层协议。
通常的,对于客户端,我们可以依靠运输层自动地分配端口号进行网络数据的传输(例如浏览器发送网络请求,我们不需要特意地去给它分配固定的端口号)。而服务器端,则需要分配一个特定的端口号。
对于 UDP协议 和 TCP协议,如上篇介绍的,UDP协议的服务器只需要一个套接字来负责接收数据,因此只需要1个二元组(目的 IP地址 和目的端口号)来确定套接字。而TCP协议使用多个套接字:1个用于负责连接握手的套接字 和 与具体用户间建立的数据传输套接字,因此,TCP协议需要一个4元组(目的 IP和端口号,源IP和端口号)来确定套接字。
需要注意的是,虽然运输层协议实际上对接的是套接字,但不同的套接字不一定对应不同的进程。例如 Web 服务器,经常会只使用一个进程,而为每个客户的连接创建一个具有新连接套接字的线程(可以当做是轻量级的子进程)。
3. 无连接运输:UDP
相较于能够可靠传输数据的 TCP协议,UDP协议仍然被广泛使用(DNS服务,网络流媒体传输,网络电话等),主要由于以下几点原因:
- 应用层对何时传输数据的可控性更高- 从发送接收控制角度来说:因为 TCP协议提供了拥塞控制机制,数据的传输的具体时间可能受到网络状况的影响。从传输延迟角度来说,由于 TCP 协议的多次握手,实际需要更多次的网络请求和相应,从而物理上需要更多的传输时间。
- 相较于 TCP 协议,UDP 协议不保存连接状态,从而可以支持更多的活跃用户。
- 分组头部的开销更小(TCP 报文需要至少20个字节的首部开销,而UDP协议仅需要8个字节)。
UDP协议只提供复用、分解 和差错检测功能。具体的实现是通过以下的 UDP头部来实现的:
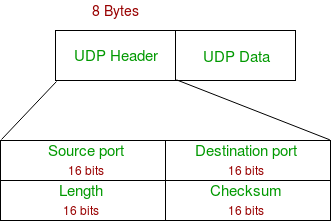
其中,长度字段指明了UDP报文段包括头部在内的以字节为单位的长度。
检验和字段提供一个对数据传输正确性的检验机制。使用下述算法:将UDP报文段中所有的数据以16个比特为单位相加(如果溢出的话,进行回卷),得到和之后,将该和取反码(按位取反),得到的结果即为检验和(checksum)。
在接收方,可以将所有的16位字节包括检验和相加,如果数据传输过程中没有出现差错,则结果一定是 1111111111111111。
在运输层添加差错检验,体现了计算机网络设计中的 端到端原则(end-end principle) RefLink:也就是尽量保持网络传输层次(底层)的简洁,尽量将具体的实现功能放置到接近应用的层次(顶层)。
4. 面向连接的运输:TCP
首先从抽象层面上介绍实现数据可靠传输的方法RefLink。
![]()
TCP 协议被称为面向连接(connection-oriented)的协议,它通过三次握手建立客户端与服务器之间的连接,然后通过差错检测、重传、累积确认、定时器、序号和确认号等机制来实现数据的可靠传输。
4.1 TCP 的报文段结构
TCP报文段的结构如下所示:
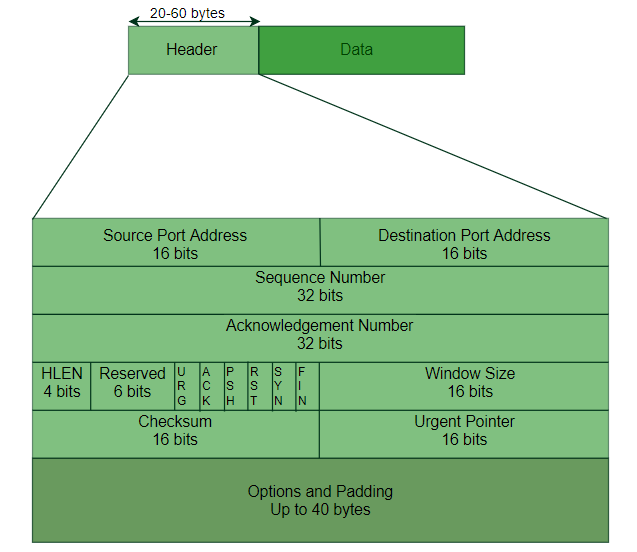
a. 序号和确认号
序号(sequence number) 和 确认号(acknowledgement number) 用于对发送的 TCP 报文进行编号和确认。例如,主机 A 需要发送500,000 个字节的文件给主机 B,规定的 最大报文长度(MSS)为 1000 字节,则发送的第一个报文序号为0,第二个报文序号为 1000,第三个为 2000,依次类推(因此实际上,系统隐式的为每个字节进行了按1递增的编号)。确认号则是主机 A 期望从主机 B 收到的下一个字节的序号。
需要注意的是,TCP 协议一般采用累积确认(cummulative acknowledgement)的机制,即只确认流中至第一个丢失字节为止的字节。例如,接收方A 接收到的字节编号为:0-535,和 900-1000,则接收方A只确认 0-535的数据,发送给 发送方 B 的确认号是 536。
b. 首部长度字段以及标志字段
首部长度字段(header length field)占用4个比特,用来规定TCP 协议头(首部)的长度。(如上图所示,TCP 协议头部长度可变,20字节到60字节)
6个标志字段中,ACK 位用于标识上面的 确认号字段中的值是否有效。
RST、SYN、FIN 位则用于连接的建立和拆除。主机A要与主机B建立 TCP连接:
- 第一步:主机A(客户机)会发送一个特殊的不包含应用层数据的 TCP 报文段- 称为 SYN 报文段,该报文段的 SYN 位被置为 1。此外,该报文的序号字段中会随机选择一个初始序号(client_isn)。
- 第二步:主机B(服务器)接收到第一步中A 发送的 SYN 报文段后,为该TCP连接分配 TCP 缓存和相关变量,并向主机 A 发送允许连接的报文字段。该报文段中的 SYN 位为1,确认号字段为 (client_isn + 1), 最后,服务器选择自己的初始序号 server_isn 放置在序号字段中。该允许来接的报文段也称为 SYNACK 报文段。
- 第三步:主机A收到来自主机B 的 SYNACK 报文段后,也进行连接缓存和变量的配置。客户机A还会发出第三个报文段,对第二步中服务器发送的报文段进行确认(确认号字段中值为:server_isn + 1), 由于连接已经建立,该报文段的 SYN 位被设置为 0。此外,第三次的报文段开始允许携带客户到服务器的相关应用层数据。
当然,客户机请求的服务不一定存在于接收到 TCP 连接请求的服务器上,例如请求的端口号为80,但服务器上在80端口并没有设置任何服务,此时,服务器会返回一个 TCP 报文段,将 RST 位设置为1,以告知客户机,所请求的服务不存在。
当所有连接完毕后,系统需要关闭相应的 TCP 连接,这时候,客户机会发送一个 TCP 报文段,将 FIN 位设置为1,告知服务器,要停止 TCP 连接。服务器接收到该报文段后,返回确认报文,并且再发送一个 服务器的终止连接报文段,同样将 FIN 位设置为1。最后,客户端确认服务器发送的终止连接报文段,连接结束。
c. 接收窗口字段
用于 TCP连接使用缓存来进行数据的暂存,如果发送方发送速率过快,则可能导致缓存溢出。因此 TCP 协议提供了流量控制服务(flow-control service)来保证不出现缓存溢出。(注意与 拥塞控制(congestion control)区分,后者是用于处理网络拥塞而引起的问题)
在 TCP头部字段中,接收窗口 (window size)用于处理流量控制。具体地,接收方通过该字段 告诉发送方当前还有多少缓存空间可用。
4.2 往返时间估计与超时
TCP协议规定了超时/重传 的方式来处理报文段丢失的问题。
在 TCP协议中,使用 EstimatedRTT 来表示平均往返时间(也就是从主机A到主机B 的平均传输往返时间)。会通过采样往返时间(SampleRTT)更新该时间:
$$EstimatedRTT = (1- \alpha)\cdot EstiamtedRTT + \alpha \cdot SampleRTT$$
通常 $\alpha$ 取 0.125。
此外,使用 DevRTT 描述采样往返时间偏离平均往返时间的程度:
$$DevRTT = (1-\beta)\cdot DevRTT + \beta \cdot |SampleRTT - EstimatedRTT|$$
在 TCP协议中,根据上述两个时间规定超时时间,可以使用下述公式:
$$TimeoutInterval = EstimatedRTT + 4\cdot DevRTT$$
通常推荐的 TimeoutInterval 初始值为1 秒,如果出现超时,会将该值进行加倍。当系统计算并更新 EstimatedRTT 后,TimeoutInterval 则由上述公式进行确认。
具体的,在实际的系统中,TCP协议还有很多协调可靠传输和系统开销的优化细节。例如使用单一的重传定时器(而不是给所有的报文段各配置一个定时器)等。
4.3 TCP 的拥塞处理机制
网络拥塞可能导致数据的传输失败,TCP协议在网络拥塞时会对发送方进行遏制,来缓解网络拥塞情况。
一般的讲,网络拥塞的控制分为两类:
- 端到端拥塞控制。在这种方式中,网络层不会为运输层的拥塞控制提供支持,端系统只能通过对网络行为的观察(例如分组丢失和延迟)来判断是否出现拥塞。
- 网络辅助的拥塞控制。在这种方式中,网络层构件(即路由器)会向发送方提供关于网络中拥塞状态的显式反馈信息。例如书中提及的一种 ATM ABR 拥塞控制形式- 允许路由器显式的通知发送方,该路由器输出链路上支持的传输速率。
TCP 使用端到端的拥塞控制机制。也就是通过实际的传输现象来判断是否出现了拥塞。具体地,TCP协议 将下面两个事件认定为 网络拥塞:1- 出现超时;2- 收到来自接收方的3个冗余ACK。
出现拥塞后,TCP协议通过控制拥塞窗口(congestion window)变量来限制发送速率。具体地,TCP使用TCP拥塞控制算法(TCP congestion control algorithm),包括3个部分:慢启动;拥塞避免;快速恢复RefLink。