数据库索引方式
MySQL 数据库底层使用 B+树完成数据的索引,本篇文章,将对B树的基础知识,以及实际数据库引擎的索引方式进行简单介绍。
1. 索引方式
数据库根据底层的存储引擎不同 [1],可以使用多种数据索引方式。常见的索引方式包括:
- 哈希索引: 只用 memory 存储引擎支持,对于单值访问速度很快。但由于使用 哈希散列表的方式进行存储,数据需要添加到内存中,比较耗费内存空间;并且范围查找、排序的效率低下。
- 全文索引(FULLTEXT):MyISAM 和 InnoDB 都支持全文索引。因为普通的索引会根据索引字段最左边几个字符进行索引排序,但如果是长段的内容,想寻找text 中间的内容,则难以查询。此时可以使用全文索引,数据库会为 文本生成一份单词清单,用于索引,效率可以大大提升。
- B树索引:B树是一种二叉排序树的变形,它的每个结点可以有多个子树,具体见下图(B树的增删操作等详情,参考[3]):
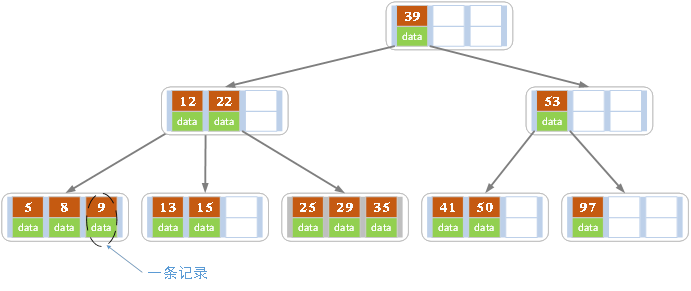
一棵 m 阶的 B 树的特点如下:
- 每个节点最多拥有 m 棵子树;
- 根节点至少有2个子树(除非B树只包含一个结点);
- 分支节点至少有 ⌈m/2⌉(向上取整) 棵子树(除根节点和叶子节点外都是分支节点);
- 所有叶子节点都在同一层,每个节点最多可以有 m-1 个 key,并且以升序排列。
B+树 是B树的一种变形,实际上数据库引擎大多使用的是 B+树索引方式。在 B树的基础上,B+ 树有如下几点不同:
- B+ 树的非叶子结点只保存索引信息,不保存数据(数据表的记录),所有数据都保存在 叶子结点中;
- 相邻叶子结点之间通过指针相互连接,并提供两个头指针,一个指向B+ 树的根结点,一个指向最左边的叶子结点;
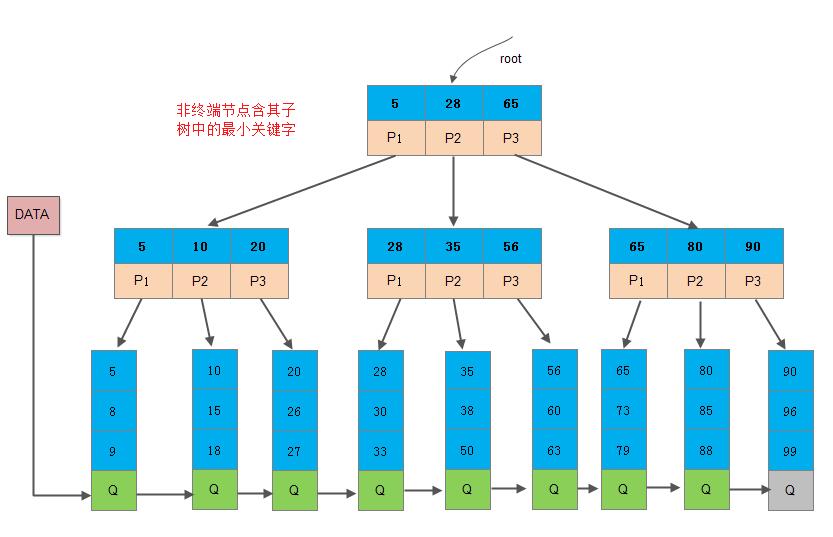
相比 B树,B+树 通过上述两点改进,可以提升数据读取性能。主要原因如下[2]:
B+ 树的磁盘读写代价更低。由于数据库读取数据通常以固定的大小进行(称为一页数据,与磁盘的存储扇区,操作系统的块,页 有关,常为 4k 的整数倍)。通过将数据全部放置在叶子结点,非叶子结点可以存放更多的索引信息,因而可以降低树的深度,降低IO 次数,提升查询效率。此外,通过添加叶子结点之间的指针,可以直接通过该指针进行数据的顺序读取,提升了数据库 区间查找的效率。
2. 聚簇索引
MySQL 的 MyISAM 和 InnoDB 都是都支持B+树索引方式,但是具体的实现上有一些细节上的差别[4]。
InnoDB 使用的 B+树结构称为聚簇索引- 数据与索引一起放置在B+树的叶子结点上;而 MyISAM 则使用非聚簇索引,数据单独放置,B+树的叶子结点中只放置数据地址。
因为数据在系统中只存一份,因而一个表 只能选取一个键作为聚簇索引,即 聚簇索引具有唯一性。在 InnoDB 中,聚簇索引默认为主键,最简单的是使用 AUTO_INCREMENT 自增列作为主键,这样的好处是可以保证数据行按顺序写入(写入效率高)。需要注意的是,应当避免使用随机值作为 聚簇索引,例如 UUID。当有大量插入操作时,随机的插入操作会让效率大大降低(因为磁盘按页读取的特性,随机插入需要频繁的切换磁盘块,从而增加 IO 次数)。
如果没有定义主键,InnoDB 会选取一个 唯一、非空的索引替代。如果没有这样的键,则会隐式的定义一个主键作为聚簇索引。
由于聚簇索引的唯一性,如果表中需要设置多个索引的话,聚簇索引模式下需要进行两次B+ 树查找 (建立两个B+树,非主键的树中叶子结点放置主键的值)。相反的,如果是非聚簇索引,则只要一次查找即可。如下图所示:
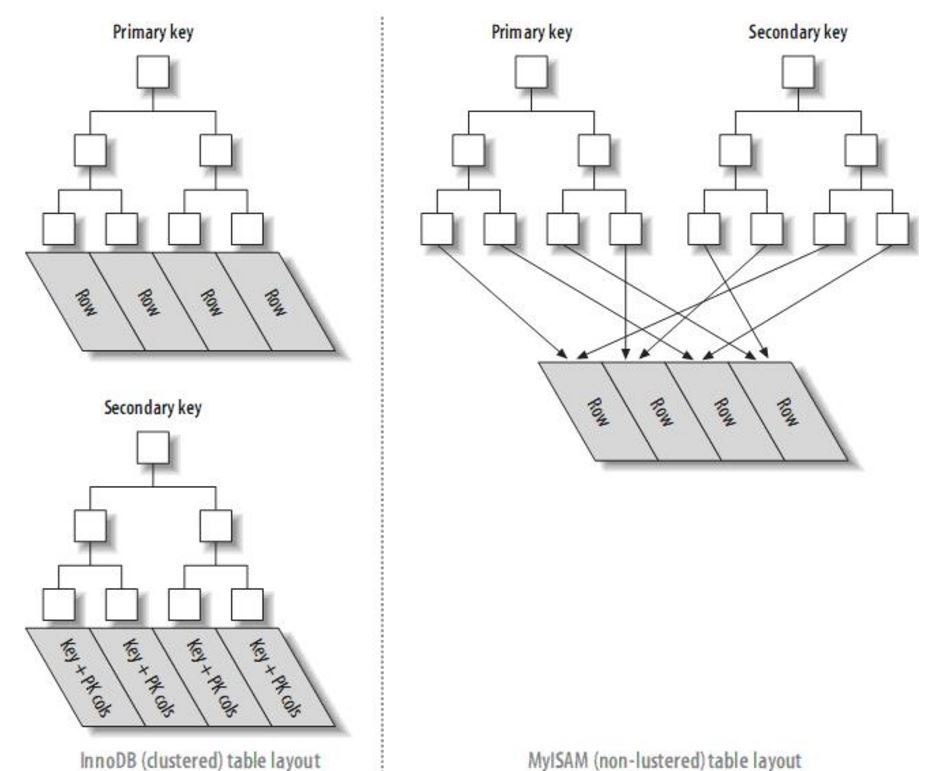
从上图中,似乎聚簇索引查找非主键列时的效率更低 - 因为需要两次遍历 树。但实际上,由于数据库数据读取的模式,数据以页的形式读取到内存中,在按主键顺序读取时,使用聚簇索引的方式可以减少 IO 次数[4]。
参考:
[1]: 数据库架构组成:https://blog.51cto.com/zpf666/1911113
[2]: 深入理解MySQL索引原理和实现——为什么索引可以加速查询?: https://blog.csdn.net/tongdanping/article/details/79878302 (文章中有一些错误,需要甄别)
[3]: B树和B+树的插入、删除图文详解- https://www.cnblogs.com/nullzx/p/8729425.html
[4] 聚簇索引与非聚簇索引 https://www.jianshu.com/p/fa8192853184
[5] 视频:https://www.bilibili.com/video/BV1K64y1F76m