Windows上安装Hadoop
为了测试方便,在 windows 上安装了 hadoop。
早期的 Hadoop 并没有提供对 windows 的官方支持, 但从 Hadoop 2.2 版本以后,开始提供对 windows 的原生支持,只是 在官网的 release 中,不包含 windows 的二进制包,需要自己进行编译 (参考)。
1. Hadoop 文件下载
除了可以自己编译,更方便地,我们可以从 github 上下载别人编译好的 windows 二进制文件,winutils。
我下载了上述 github 主页中最新的 Hadoop2 二进制文件- hadoop2.8.3。(更新的版本参考这里)。接着从 apache 的 archive 文件中下载 2.8.3 版本的 Hadoop 文件(link)hadoop-2.8.3.tar.gz。
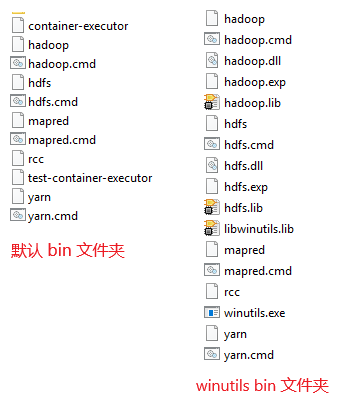
下载完成后,解压 hadoop-2.8.3.tar.gz,我将解压的文件放置在了 E:\Tools\hadoop-2.8.3 文件夹下。然后,复制 从github 上下载的 winutils 文件中 hadoop-2.8.3 文件夹下的 二进制 bin 文件夹 到上述目录下,覆盖官网下载的 hadoop 文件中的 bin 文件夹。两个bin 文件夹中文件的差异如下:
2. Java 配置
官网说明中,Hadoop 2.7-2.10 支持 java 7 和 java 8 两个版本,具体的版本支持信息参考 官网java版本说明。 由于之前电脑上安装的java 版本较高,所以重新下载并安装了一下 java 7 版本。
Java 安装完毕后,需要进行环境变量的配置,全部在 user 环境变量下进行即可 (User 环境变量与 system 环境变量的区别)。主要包括两个部分:
- 添加字段: 加
JAVA_HOME和HADOOP_HOME两个字段。我的系统中,JAVA_HOME = C:\Program Files\Java\jdk1.7.0_80。 - 修改 PATH 变量,向原有 path 变量中追加添加:
%HADOOP_HOME%\bin,%JAVA_HOME%\bin,%HADOOP_HOME%\sbin。
3. Hadoop 配置
上述安装全部完成后,需要对 Hadoop 的相关配置文件进行修改。
我进行的修改如下:
Step1: 修改 etc\hadoop\hadoop-env.cmd 文件(用文本编辑器打开)、将其中的 java path 设定 由 set JAVA_HOME=%JAVA_HOME%。 改为 set JAVA_HOME=C:\Progra~1\Java\jdk1.7.0_80。
进行修改的主要原因是 Java 安装在了 Program Files 文件夹中,从而在路径中引入了空格。 而 Hadoop 这里的路径不支持空格。避免使用 空格的办法是使用 windows 对 Program Files 文件夹的简称:Progra~1。(参考)
Step2: 编辑 \etc\hadoop\core-site.xml 文件, 在 <configuration> 中添加属性如下。
1 | <configuration> |
Step3: 编辑 \etc\hadoop\hdfs-site.xml 文件。
首先在 hadoop-2.8.3 文件夹的 根目录下添加 data 文件夹,再在该文件夹中添加 datanode 和 namenode 子文件夹。
最后在 hdfs-site.xml 中添加 properties 如下:
1 | <configuration> |
Step4: 修改 \etc\hadoop\yarn-site.xml 文件,如下:
1 | <configuration> |
Step5: 重命名 etc\hadoop 文件夹下 mapred-site.xml.template 文件 为 mapred-site.xml。编辑 \etc\hadoop\mapred-site.xml 文件如下:
1 | <configuration> |
Step6: 在 cmd 中执行指令 hdfs namenode -format。注意由于已经在环境变量的 path 中添加了 Hadoop 的 bin 目录,所以上述指令可以直接执行。
执行完毕后,会看到在上述 hdfs-site.xml 文件中指定的 namenode 和 datanode 文件夹中添加了一些初始化文件。
Step7: cmd 中执行 start-all.cmd, 启动 Hadoop 服务。
Note: start-all.cmd 是个比较旧的指令,执行的话会返回如下 log:
1 | This script is Deprecated. Instead use start-dfs.cmd and start-yarn.cmd |
也就是推荐分别执行 start-dfs.cmd 和 start-yarn.cmd。 这与 官方文档 中的步骤一致。
上述配置过程 主要参考了 1、2、以及 官方文档。在官方文档中,提到上述 step1-3 主要是配置 HDFS;step4-5 则是对 YARN 进行配置;step6 用于对文件系统进行初始化;最后step 7 启动程序。